English
English
Evaluating AI: Your Guide to Using Golden Test Sets
By Paul Edwards
05/27/2024

With the influx of new AI capabilities that vendors are adding to their software, ecommerce leaders need a better way to evaluate which tech fits their use cases. There’s no such thing as the best AI for all companies — there’s only the AI that’s best for you, your data, and your customers.
Most companies are still using RFPs to evaluate AI tools, but the standard feature checklist (with an explanation of each feature) isn’t effective at measuring whether the AI is delivering actual value. All vendors have access to essentially the same foundational models — the difference will come from how they have fine-tuned those models and applied them to problems worth solving.
The normal tactic of asking for case studies and references doesn’t necessarily work either, not only because these features are new and unproven, but also because their results depend heavily on the product and customer data you feed them.
Instead of trying to make a better RFP, ecommerce leaders should borrow the concept of a golden test set from AI model companies and adapt it for their business. Let’s dive in.

What Is a Golden Test Set?
A golden test set is a collection of test scenarios that has been curated by human experts and is used to evaluate AI model performance. The set is designed to cover key scenarios that the AI is designed to solve. So, whenever a company releases a new version of its AI model, it tests the model’s performance against this test set so the company can evaluate progress over time in a standardized and objective way. This makes it easier to make informed decisions about which model is the best to deploy.
To make this work for ecommerce product discovery, companies should create their own golden set of test questions and scenarios that they can test vendors against. While this is immediately useful for anyone planning to replace their search technology soon, it’ll also be useful for future-proofing your processes. As vendors get more aggressive in reaching out about their latest AI innovations, this will be an easy way to benchmark them against current performance.
Perhaps most importantly, it’ll help ground you as current and future vendors tell you how they’re incorporating new AI models into their technology. By testing against your own golden set, you cna more easily determine whether the vendor’s technology actually creates business results for you.
How To Create Your Golden Set
When creating your own version of a golden set for product discovery, you can certainly start from scratch. However, if you’d like some guidance and advice, try using Bloomreach’s recommended set (detailed below) and tweaking it for your needs.
Step 1: Analyze Your Queries
Most search engines are sophisticated enough to apply different AI strategies to different types of queries. A simple example is head queries vs. long-tail queries. Head queries with one or two words are easy to return results for with semantic or even keyword search, whereas tail queries benefit from broad approaches like vector embeddings.
Therefore, your golden set should include a broad set of query types that represent the searches that actually happen on your site. You can analyze your search data to figure this out. If you need a starting place, here are some common types of queries:
- Top queries by search volume
- Top queries by most revenue
- Tail and torso (2+ words in the query)
- Random sampling
- Null searches
- High exit rate queries
- High bounce rate queries
- Low/no revenue queries
- Low ATC rate search queries
- Queries with no product clicks
- Queries with recent increases in traffic
- Queries with recent decreases in performance
Step 2: Determine Your Split
Once you’ve analyzed your query types, you’ll need to decide how many examples of each one you want to include in your golden set.
Your first instinct might be to simply go by percentage. That is, if 80% of your queries are head queries, then that’s how many should appear in your golden set. However, it’s not quite that straightforward.
Some query types are trickier for AI technology to get right than others, and those are the ones you want to make sure have good representation within your golden set.
To return to our head queries example — most search engine technology can handle these well even without sophisticated AI. You should include some in your golden set just to be sure, but you certainly don’t need 80%.
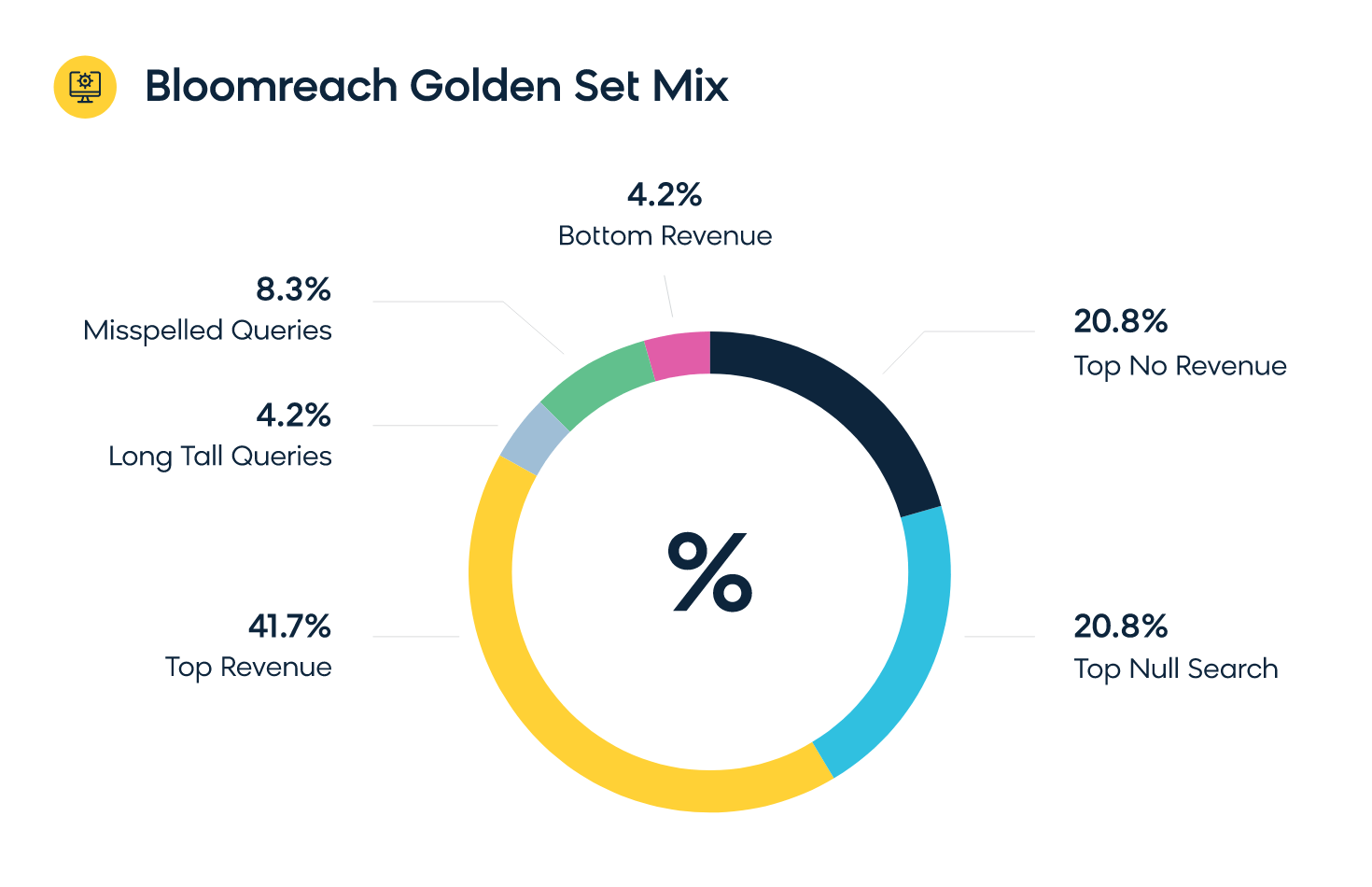
Here’s how Bloomreach typically creates a golden set when running relevance reports for our customers:
- Top 500 no revenue queries
- Top 500 null search queries
- Top 1,000 queries by revenue
- 100 torso queries - random sampling
- 100 long-tail queries - random sampling
- 200 misspelled queries
- Bottom 100 queries by revenue
Once your golden set is complete, you can move on to running your evaluation.
How To Run Your Evaluation
Methodology
- Run your current technology against the test set and create your benchmark. Note: some of the benchmark results will return a negative result by design (e.g., null search queries). This is intentional. In the next step, you’ll see whether the new technology you’re evaluating can beat that zero benchmark.
- We recommend using what we call the “eyeball test” to score your results. Type in a query — when you look at the search results it returns, are they what you expect to see? Another way to think of it is, are these the results a rational human would expect to come back for this query? If so, give it a score of 1. If not, give it a score of 0.
- Score all vendors you’re evaluating against the same golden set. To read the results, simply look for the highest scores for each query type. There won’t necessarily be a clear winner — some vendors excel at particular query types but have weak performance in others. You’ll need to decide which types are most critical for your business needs. Since you’re using your own data, you should be able to make a strong guess at which improvements will translate into the most revenue for you (and the vendor can likely provide guidance here as well).
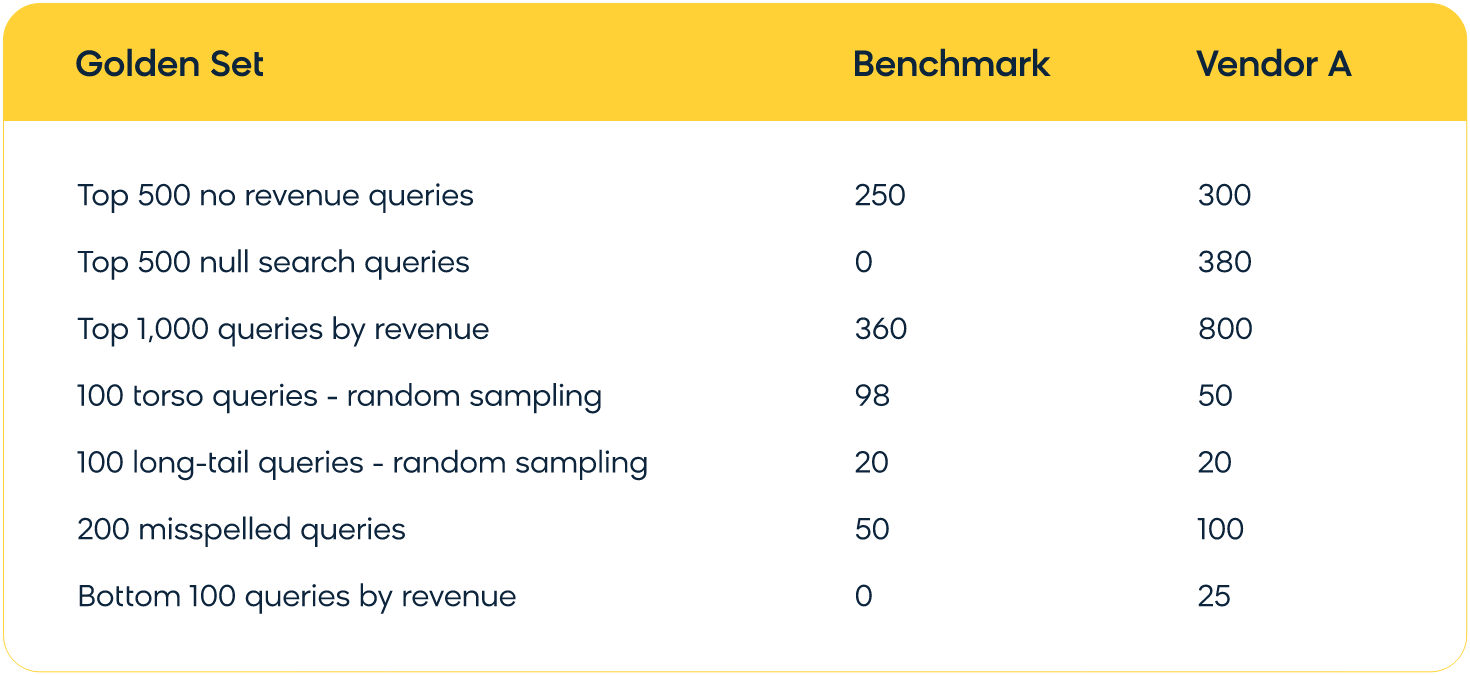
Example scorecard: This demonstrates that, across most categories, Vendor A consistently returns better results than the benchmark.
The above process is somewhat subjective, but then again, so is relevance. What one person considers a good result for their customers, another might find confusing. It’s okay to pick the result that’s biased toward the customer experience you want to achieve for your business.
A note on ranking — you may be wondering at this point how to evaluate ranking optimizations and tools. All vendors should offer some level of AI to automatically optimize ranking for a particular goal (usually revenue). This is easier to evaluate with an RFP since the vendor should offer specific tools that you can see in a demo or try for yourself in a POC environment. After you test a vendor’s AI against your golden set, you can highlight the weakest areas and ask the vendor to show you how the tools they provide will help you optimize those areas further.
Working With Vendors’ Evaluation Processes
Not all vendors offer the same testing capabilities in pre-sales. Here are some tips for asking a vendor to work with your golden set during the evaluation process.
If you’re offered a sandbox, run the test yourself without configuring any rules. Remember, the goal of the golden test set is to evaluate the core AI. Every solution will offer some options to improve on top of the AI foundation, but by comparing the OOTB without configuration, you can compare the AI performance apples to apples across vendors.
If you’re offered a POC — something where the vendor stands up a demo site to show your results with their AI — ask them either to use the golden test or to give you access to the demo so you can do it yourself.
If you’re only offered demos that the vendor controls, try asking if they’ve ever done any internal benchmarks of their AI against any of the scenarios you’ve chosen to focus on. If the answer is no, maybe AI isn’t a core function of that company.
Put Your Data to the Test Against Bloomreach Discovery
If you’re looking for a new product discovery solution, Bloomreach Discovery is your best bet to drive impactful results fast. Powered by Loomi, an AI built for ecommerce and fine-tuned with 14+ years of data, Bloomreach Discovery empowers you to improve the metrics that matter most for your business.
See how your golden test set fares with Bloomreach Discovery by requesting a search impact validation today.
Found this useful? Subscribe to our newsletter or share it.

Paul Edwards
Technical Product Strategist at Bloomreach

Christine Reyes
Product Marketing Manager at Bloomreach
Paul is a Technical Product Strategist versed in fields as diverse as ecommerce, machine learning, telecommunications, and aviation. He spends his time focussing on the application of cutting-edge technologies and hybrid algorithms in the ecommerce space. His spare time is consumed with the renovation of a cottage in the Surrey hills.
![]()
Christine Reyes oversees product marketing for Bloomreach Search & Merchandising to help companies build great commerce experiences.
![]()