English
English
Using AI-Based Multilingual Entity Detection To Build a Robust Semantic Understanding Capability
By Data Science & Search Intelligence Platform Team
12/22/2022

Introduction
With the rapid evolution of search engines and recommender systems, end users are able to quickly explore and find the items they need. In spite of this, the majority of the available solutions are not “intelligent” enough. There is a huge semantic gap between what users’ intentions are and how the items are organized in ecommerce sites.
Lately, there’s been a huge shift from using the traditional “bag-of-words” approach based on classical inverted index. For product search, end users often look for specific items. In order to deliver a delightful experience, it’s very important to retrieve a highly relevant set of products while eliminating irrelevant items from a very large collection of products. In the case of a recommender system, there is a need to provide solutions to serve relevant products based on similarities derived from a product's metadata and the user's preferences.
Being the industry leader in the commerce experience space, Bloomreach has been delivering precise and relevant search and recommendation solutions — in multiple languages. Our solutions are designed and backed by sophisticated in-house foundational components. Entity detection is one of those key components powering various end user-facing applications.
Our team has been looking at different ways to extract underlying product attributes (product type, color, style, dimension etc.) in a very accurate manner to deliver precise results and improved ranking. As shown in the following figure, in the case of a user looking for a “black laptop,” displaying a black “laptop case” in the result set will not be a great experience.
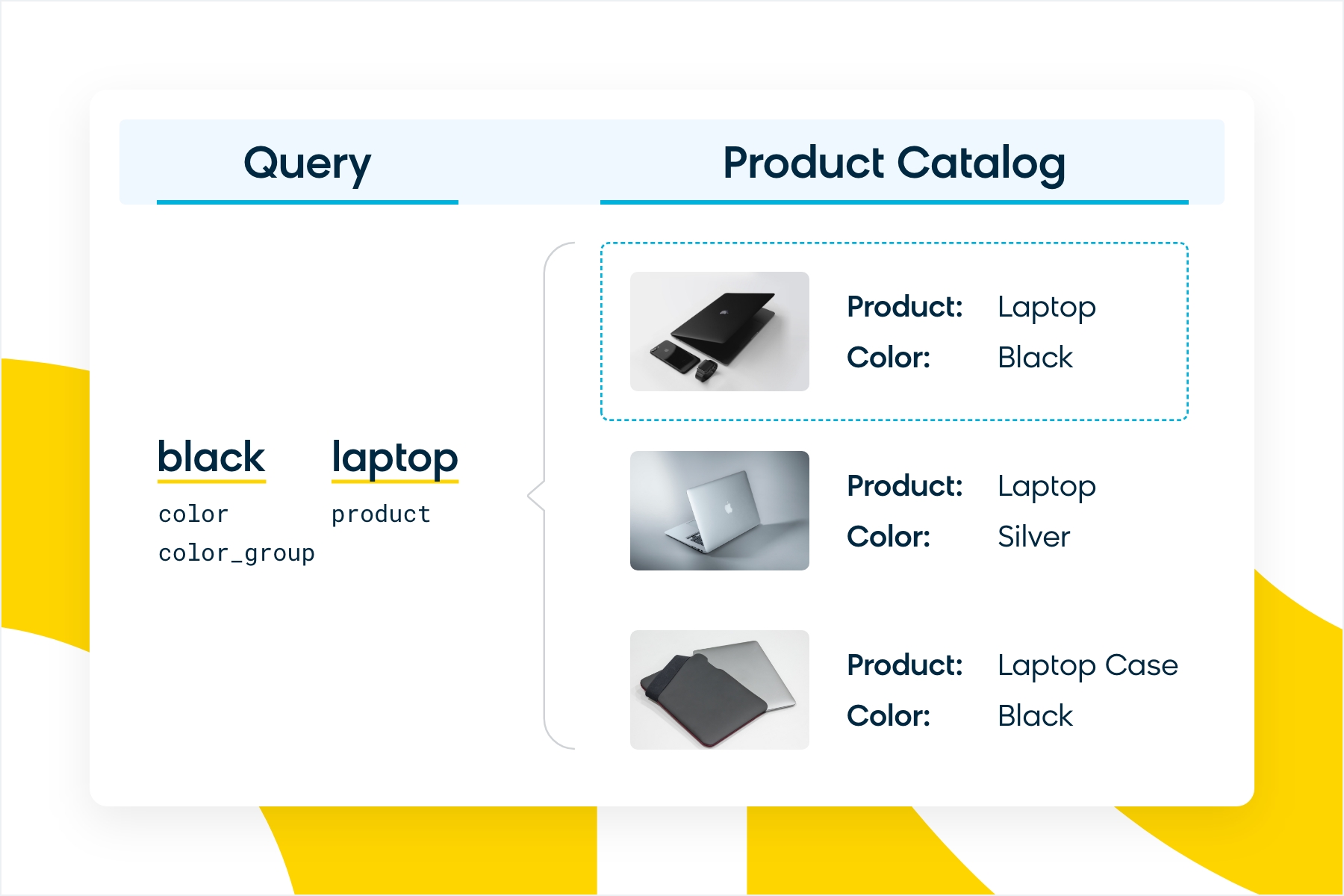
Over the years, Bloomreach has put significant effort into learning a rich set of commerce-specific product attributes, product aliases, and taxonomy. These get utilized to better understand product and query semantics to empower search. We use this in multiple additional areas of our application such as facet relevance, automated suggest generation, SEO, etc.
So far, our efforts have been primarily geared towards English-language product feeds. As we expand our business rapidly across multiple geographies, there is a need to expand this capability beyond English only. In order to solve this problem, we have extended our attribute detection solution with French and German product feed languages. We’ve done this by exploiting the latest in deep learning-based language modeling.
AI-based Automated Attribute Detection
We have formulated the problem of automating the attribute extraction process from product titles and queries as a Named Entity Recognition (NER) [1] problem with multiple attribute labels. The absence of syntactic structure in such short pieces of text makes extracting attribute values a challenging problem. In the past, many machine learning approaches have been devised to solve this problem (e.g., CRF [2]). But with the recent advancements of deep learning-based techniques [3], there has been a huge focus to solve this utilizing sequence-to-sequence modeling (e.g., RNN, BiLSTM) and transformers-based approaches (e.g., BERT [4]).
Our AI-based deep learning approach exploits embeddings to cluster similar tokens together. So, even if a token is explicitly not present in the product feed of training data, it can be tagged because of its neighboring tokens. In addition to this, the AI-based approach is agnostic of textual patterns observed as part of the product feed.
Our model of choice was BERT for generating embeddings with a token classification head on top for the actual NER task. We used the BERT for Token Classification [6] pre-trained model provided by Huggingface and trained the same on our dataset in two phases:
- Phase 1 (unsupervised pre-training) — Where we pre-trained the BERT model on our unlabeled dataset using Masked Language Modeling [7] to help the model learn general knowledge about the ecommerce domain
- Phase 2 (supervised fine-tuning of headers) — Where we fine-tune the token classification head on our labeled dataset for NER
We found using this two-phase approach of a pre-training followed by fine-tuning helped us achieve better results as compared to just a task-specific fine-tuning on our labeled dataset.
We have built specific models to perform attribute extraction in French and German. Hence the pre-trained language models we used were trained from scratch on the respective languages.
- CamemBERT [8] for French which is trained on approximately 138 GB of French text
- German BERT [9] for German which is a language model open-sourced by the MDZ Digital Library team and is trained on approximately 16 GB of German text
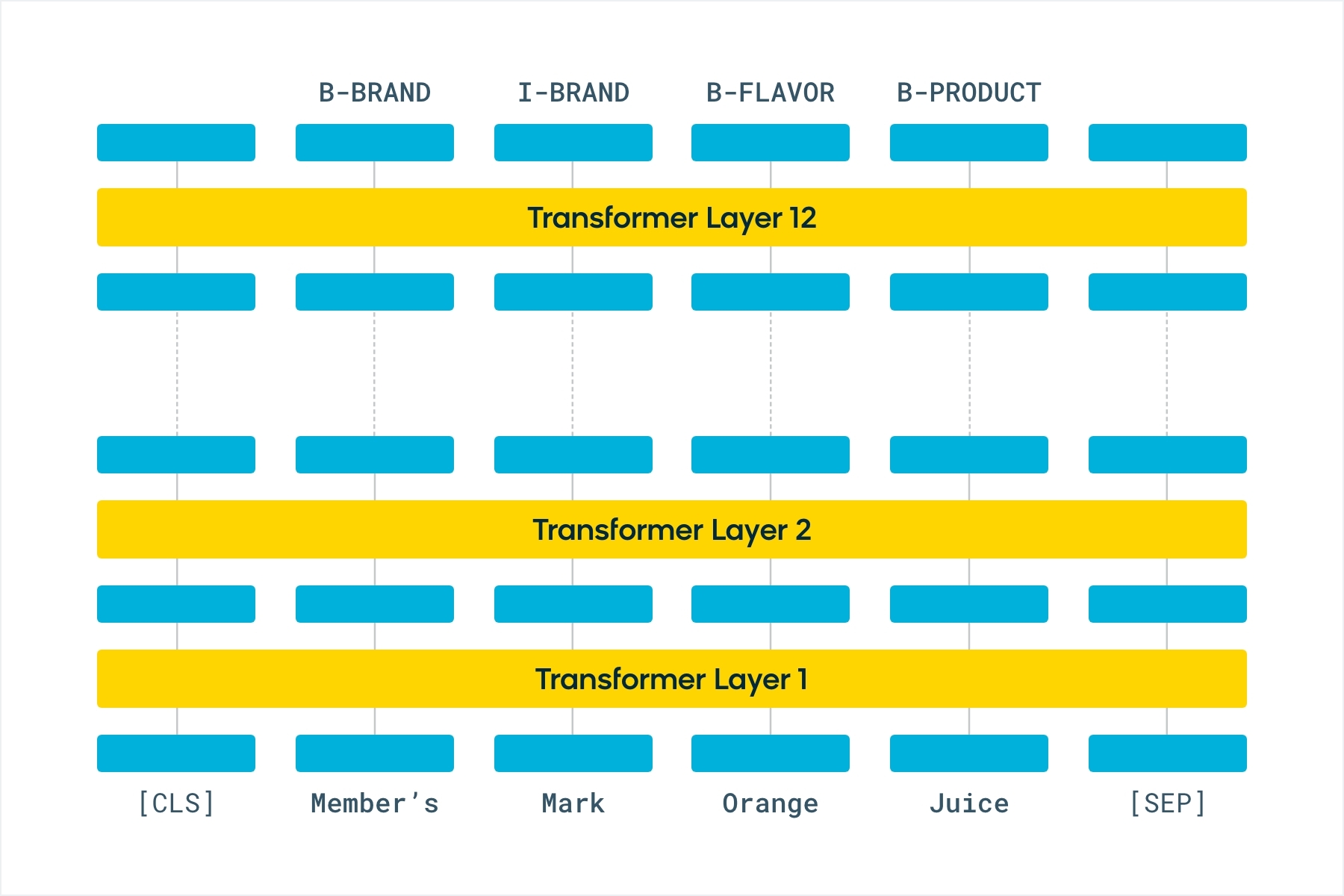
We have worked with multiple merchants to validate model adaptation on diversified domains (e.g., apparel, grocery, industrial supplies etc.). We observed that BERT for token classification model outperforms BiLSTM. In particular, BERT is better at recalling labels for tokens it has seen in the training data, even when those tokens occur in varied contexts and title patterns.
Training Data Creation
NER is a supervised task where each token in a sentence has to be assigned a label based on the entity they belong to. The tokens are generated by passing the input sentences through a tokenizer which splits each word in the sentence into one or multiple pieces. BERT models use what is called a WordPiece [10] tokenizer to help identify related words which may share some of the pieces or tokens. We use the BIO or IOB tagging format [5], where the first token of an entity starts with B- (or begin) tag and all tokens that follow the first token for the same entity start with I- (or inside) tag. All tokens that do not belong to any entity of interest are assigned the O (or outer) tag.
Labeling millions of tokens across several hundreds of thousands of product titles and queries to generate a training dataset is a time-consuming and tedious task, and brings with it possible inconsistencies and human bias if done manually.
That’s why we leveraged our already precise and proven attribute extraction capabilities we have for English to create an automated training dataset that can not only be generated in a short span of time, but is also scalable in the sense that we can add new entities or iterate over tagging to make corrections with fast turnaround times, which is quite difficult to do manually.
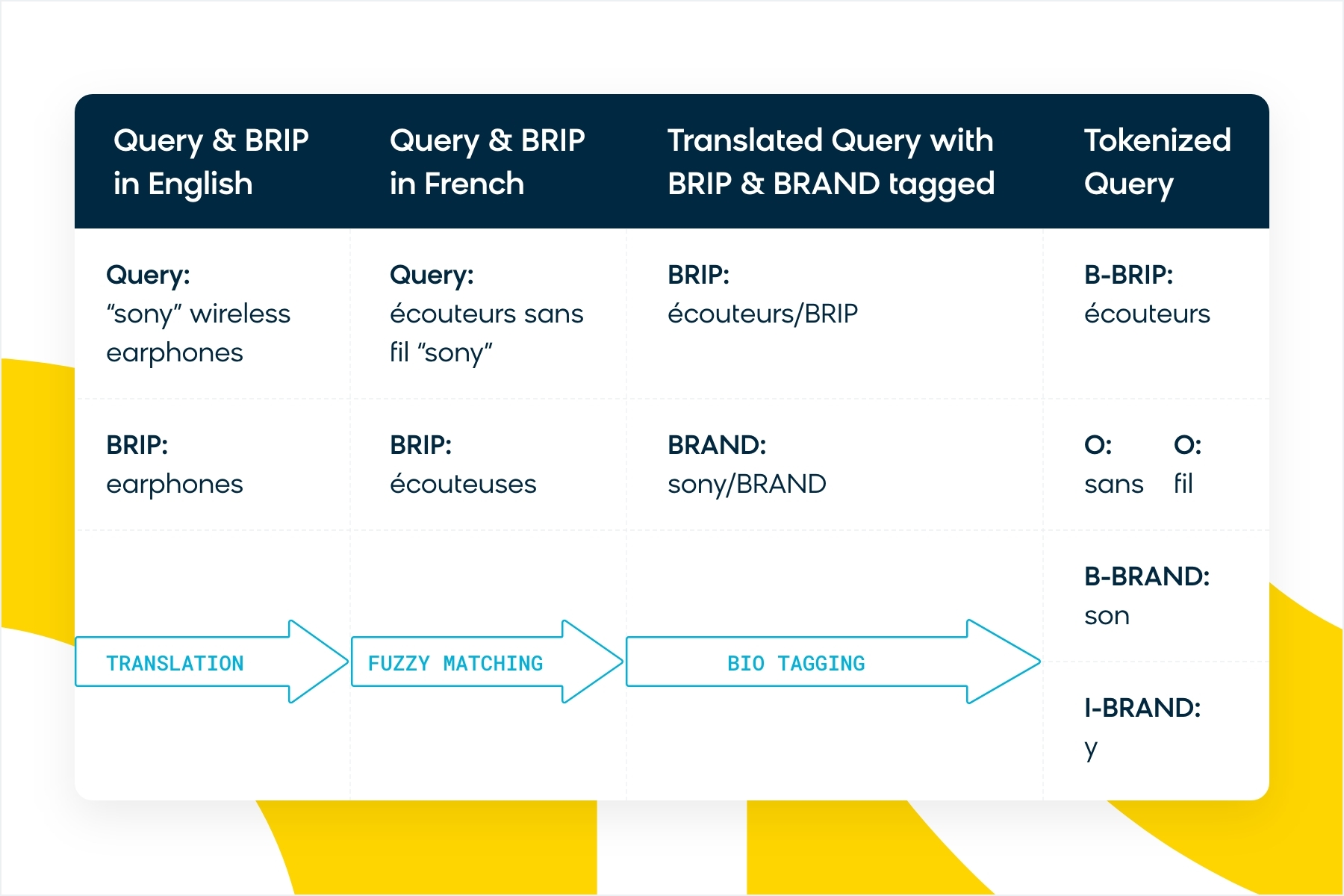
As we chose language models which were trained from scratch in either French or German only, we had to get our English datapoints translated into the target language in order to further pre-train the models with our data. However, the most challenging part of the translation was to preserve the labels that we had in English after translation. There is no guarantee that the positions of words would remain the same after translation, as each language has its own structure. For example, the query “blue couch cushion” in English translates to “coussin de canapé bleu” in French. In order to locate the product type after translation, we got the product types translated separately and then tried to match it with all the words in the translated query using a fuzzy-match logic. We used a fuzzy-match logic instead of an exact match as there is also no guarantee that the translation of a certain word along with other words in a query will be the same when done separately without any surrounding context. For example, although “earphones” translates to “écouteuses” in French, the query “wireless earphones” translates to “écouteurs sans fil.”
Besides translating actual English queries and product titles, we programmatically generated synthetic queries as well, which helped us improve recall and coverage.
Using the following method, we were able to generate a dataset of approximately 2.32 million data points in French and approximately 2.03 million data points in German in a few hours, which would otherwise have taken weeks — if not months — if done manually.
We also got around 500 product titles and 500 queries for each of our French and German customers manually tagged for testing the model.
The various steps in the training data generation process has been depicted in the this diagram:
Results
Offline Evaluation
We set aside a test dataset of about 10% from over 2 million data points, on which the accuracy across epochs reached up to 98%. Apart from a test split, we also prepared a manually tagged dataset for both French and German.
Online Evaluation
While we A/B tested the model against the current setup for a selected set of merchants, we have seen a significant RPV lift of 4%. After we launched the model in production, we have witnessed a significant drop for null search results after the model is deployed. As an example, for a merchant we have seen a drop of almost 27% for null search results.
Fast Online Inference
BERT is exceptionally good at language modeling and gives excellent results on the task of extracting attributes from product metadata and search queries. Part of it can be attributed to the size of the model — it has over 100M parameters, resulting in models which are over 400 MB large.
Deep semantic understanding of both product metadata and search queries is needed to achieve highly relevant results. Since product catalogs are largely static, the model can be used relatively easily in an offline, batch-inference setting to extract attributes from all products. However, the gigantic size of the BERT model poses a challenge on query-side extraction: Each search query needs to be tagged in real time to extract meaningful attributes from it and match them against pre-extracted product attributes.
Quality and speed are equally important for delivering magical ecommerce search experiences. While a well-trained BERT model delivers on the quality, we also need to crack the code of fast inference to keep search blazing fast. The raw model, without any inference-centric optimization and tuning, is able to deliver a 95-percentile latency of 50 ms at 15 QPS and 110 ms at 80 QPS when run on a 16-core CPU. As a small part of the overall search solution at Bloomreach, which caters to ecommerce traffic at thousands of QPS with an average latency in the low hundreds of milliseconds, these numbers are not acceptable.
The most straightforward way of speeding up inference is to cache the model predictions for each query. With a limited cache size and a virtually unbounded set of unique queries entered by millions of users of Bloomreach customers, this strategy alleviates latency concerns only for popular queries. For a vast majority of tail queries, which are not seen often, there’s a high likelihood of cache-miss, necessitating the need for fast real-time model inference.
We experiment with different optimization techniques and tune our serving infrastructure configurations to bring down the latency of online inference.
Dynamic Quantization
Model parameters are 32-bit floating point numbers. Most CPU chips are able to perform 8-bit integer calculations faster than 32-bit float calculations. Dynamic quantization exploits this by converting the float model to a quantized model with int8 weights and activations, reducing its size and improving inference performance.
Quantizing the weights and activations of the model after training can hurt the quality of its predictions. In our tests, the accuracy of the BERT model dropped only marginally (less than 1%) after quantization, but led to significant improvements in inference performance. An alternative is to apply quantization during training, where the idea is to force the model to learn integer weights as it is being trained, ideally without compromising the quality of predictions.
ONNX Runtime
ONNX Runtime is a cross-platform training and inference accelerator for ML models. It optimizes the model for the hardware on which it is being run by leveraging dedicated parallel programming libraries like OpenMP, Intel DNNL, and CUDA. It also runs mathematical and graph optimizations to reduce or combine certain operations and make them faster. Unlike dynamic quantization, these optimizations are lossless and do not affect the quality of predictions.
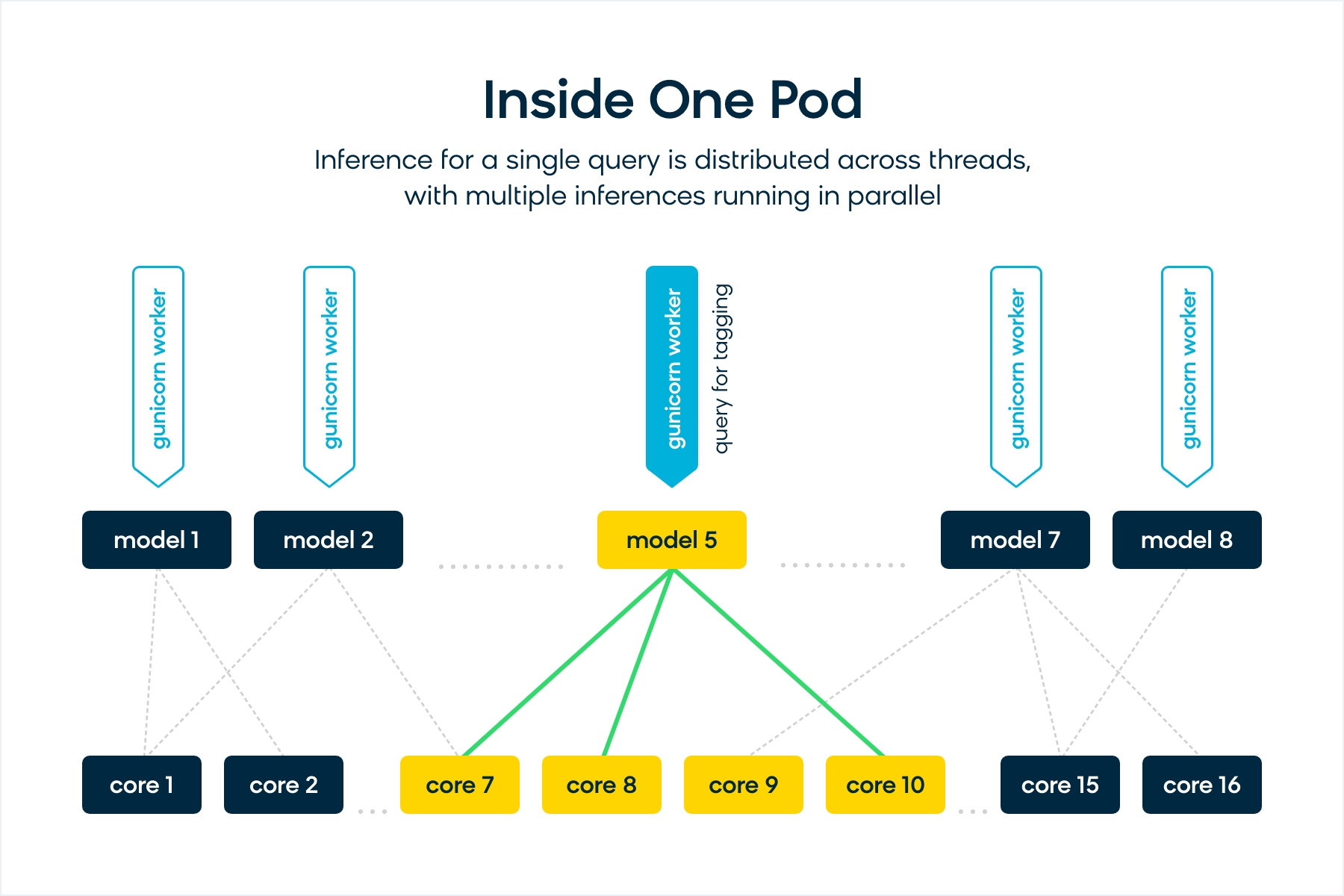
Gunicorn Server and ONNX Runtime Thread Tuning
Our Attribute Extraction (AE) inference server consists of the trained (and optimized) BERT model hosted in a simple Python webapp behind a Gunicorn HTTP server. Gunicorn provides different configurations to control throughput and latency of the webapp. ONNX Runtime built with OpenMP also provides several configurations to tune the number of threads per inference through onnxruntime.SessionOptions parameters like inter_op_num_threads and intra_op_num_threads, and through OpenMP environment variables like OMP_NUM_THREADS and OMP_WAIT_POLICY.
The figure shows a simplified view of what goes on inside each ML inference server pod.
To tease out the impact of each of these optimization knobs, we ran several performance tests. The following section summarizes the test setup and lists some of the observations.
Test Setup and Observations
- One Linux machine with 32 GB memory and 16 cores on an Intel(R) Xeon(R) Platinum 8124M CPU @ 3.00GHz chip
- Model deployed as a Flask app behind gunicorn and ngnix
- 8 gunicorn workers — 8 copies of model loaded in parallel for better throughput
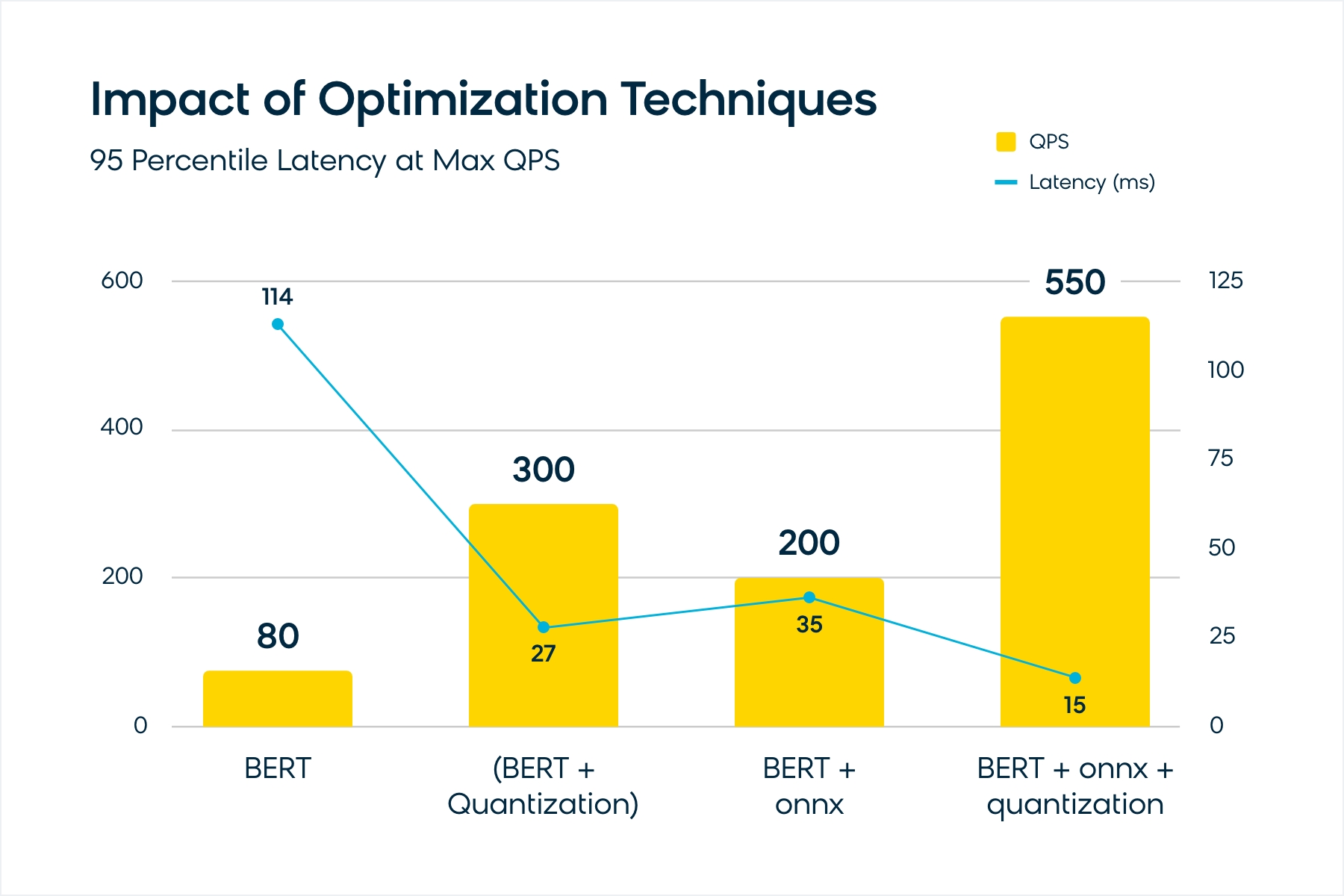
The chart below shows the impact of several optimization techniques on model performance. It shows 95-percentile latencies at the max QPS (the QPS after which some of the requests start timing out). The latencies could be lower at lower QPS for the same setup.
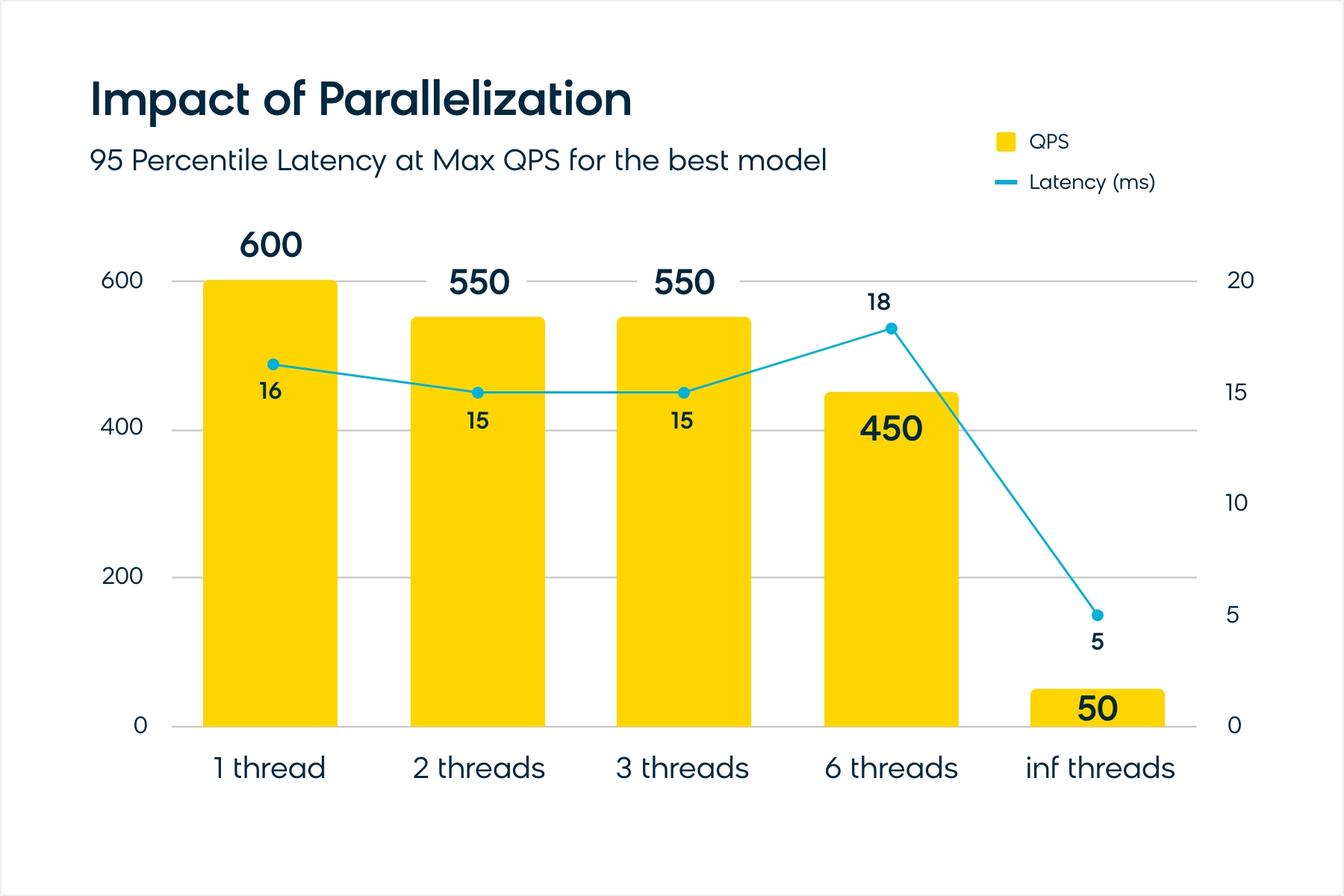
The number of threads allowed per inference also impacts the latency and throughput. The chart below shows its impact on the setup with BERT + ONNX + quantization.
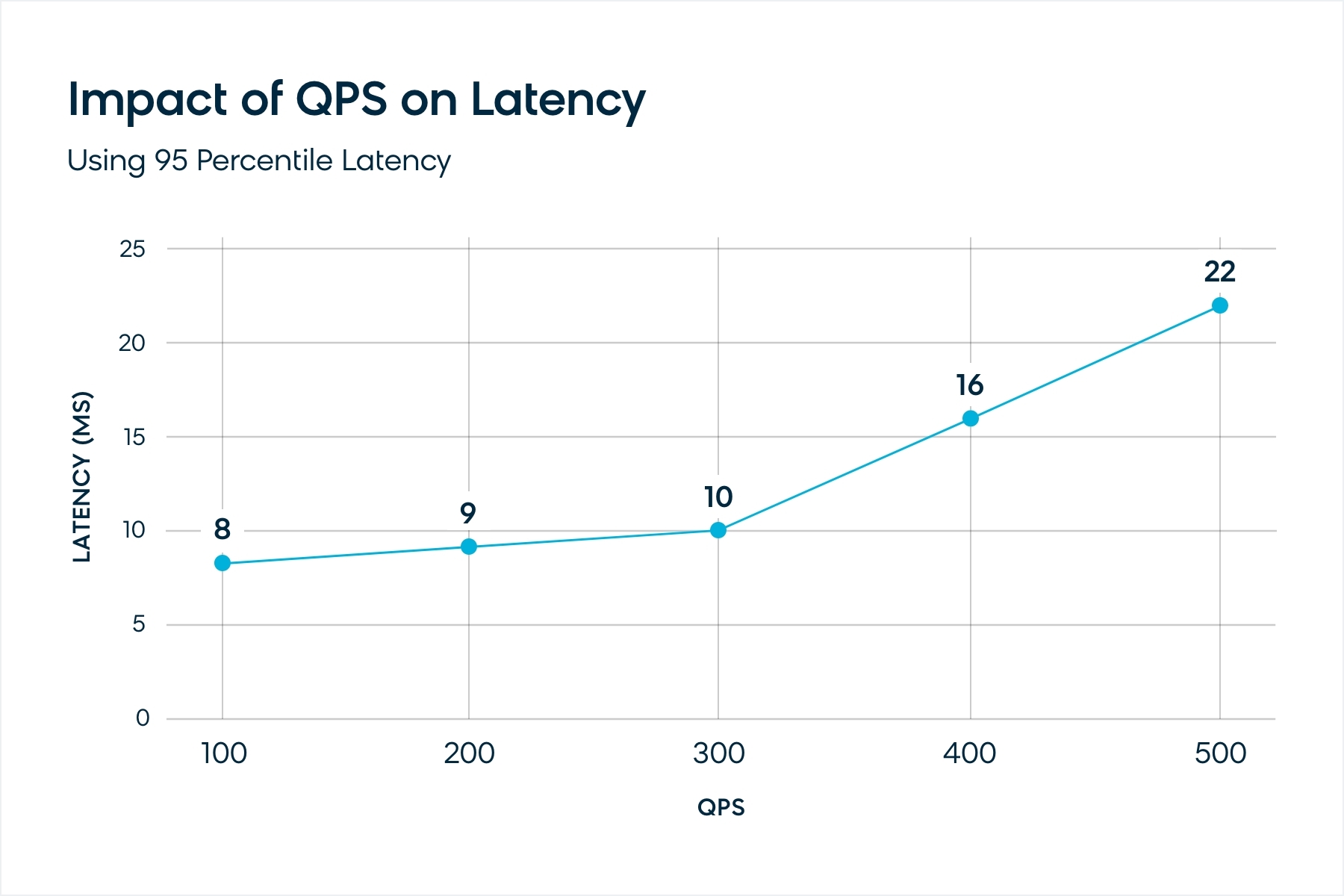
With multiple threads per inference and multiple replicas of the model running in parallel, there is resource contention between different model replicas for cores. For the same setup, then, latency increases with increase in throughput. The chart below shows this trend for the BERT + ONNX + quantization model using six threads per inference.
At the end, we carefully evaluate the optimization options and inference server configurations available to us, balancing the trade-off between model prediction quality, inference latency, throughput, and infrastructure cost to host the model.
Model Serving Architecture
Serving infrastructure to host NLP-based attribute extraction models is designed to support live traffic of our customers. It is lightning fast and highly scalable.
We follow the microservices principles and map our design into multiple services: AE Frontend service and language-specific AE model inference services.
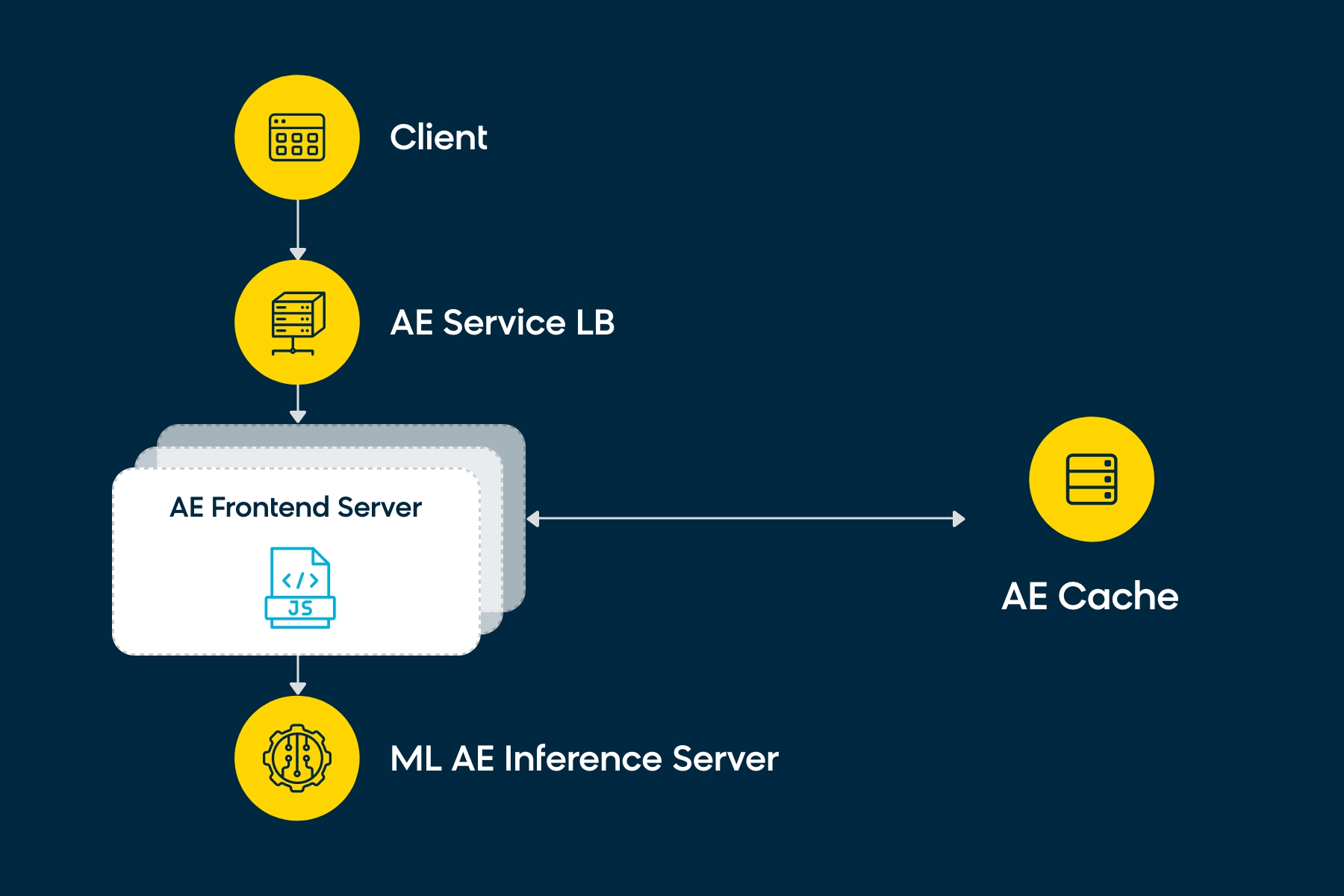
To achieve auto-recovery and scalability, we containerize our work loads and use Kubernetes as the container orchestration tool. Our choice to adopt microservices-based architecture gives us the flexibility to scale each service independently. For example: AE Inference service for German can be scaled independently of the AE Inference service for French if the traffic patterns dictate such a need. This enables us to optimize serving infrastructure and avoid resource waste.
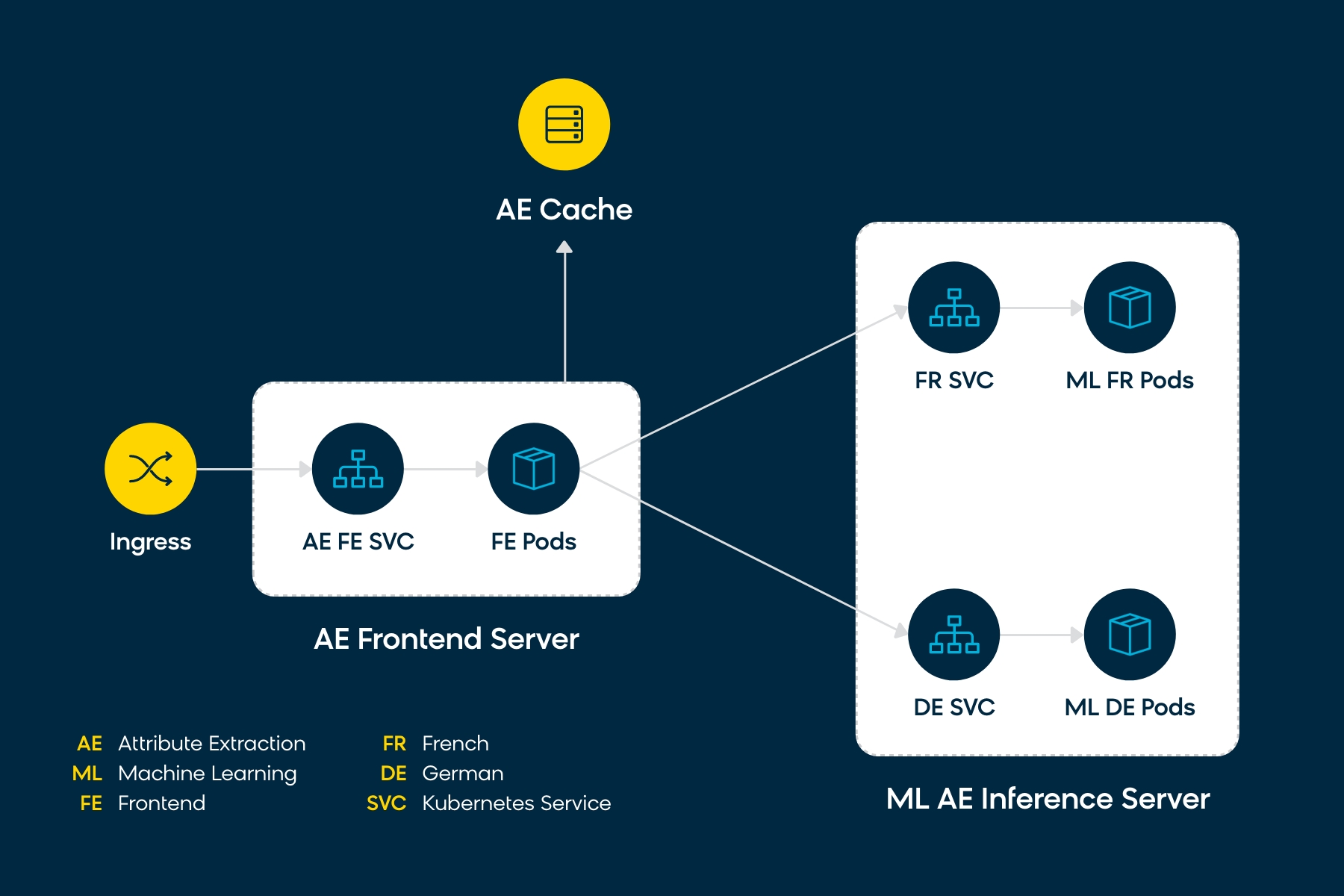
Our serving architecture is highly extensible. We can add support for a new language without any changes to the existing architecture. We also have the flexibility to isolate a customer to a dedicated environment, say, by spinning up a customer-specific AE Inference service which hosts a model trained to satisfy their specific use cases.
Observability is a key aspect of ensuring a stable and reliable service. We use Kubernetes service mesh, implemented by Istio, to provide observability and reliability features at the platform layer. Because these features are available at the platform layer, it allows the application layer to focus exclusively on its core functionalities. We use industry-standard tools like Prometheus and Grafana to collect and display observability metrics. Our setup ensures that we are able to take corrective actions proactively before any major issue is observed.
The Way Forward
As a next step, we will be focusing on scaling up the NER model incorporating an increased number of merchants/domains.
Our serving infrastructure is robust and performant. Its latency metrics are well within our SLAs and it has added immense value to the Bloomreach Discovery product.
We plan to experiment with a few more techniques to achieve significant speedups in inference (both online and offline). One of them is distillation, where a smaller student model is trained to replicate a larger teacher BERT model. DistilBERT [11] is a “distilled” version of BERT which has been shown to retain 95% of quality of the original BERT while using only 40% of the parameters.
References
- Wikipedia. (2022). Named-entity recognition.
- Sutton, Charles & Mccallum, Andrew. (2010). An Introduction to Conditional Random Fields. https://arxiv.org/abs/1011.4088.
- Li, Jing & Sun, Aixin & Han, Ray & Li, Chenliang. (2018). A Survey on Deep Learning for Named Entity Recognition. http://arxiv.org/abs/1812.09449.
- Devlin, Jacob & Chang, Ming-Wei & Lee, Kenton & Toutanova, Kristina. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. https://arxiv.org/abs/1810.04805.
- Wikipedia. (2022). Inside–outside–beginning (tagging).
- HuggingFace. BertForTokenClassification
- HuggingFace. Masked Language Modeling
- HuggingFace. CamemBert
- HuggingFace. German Bert
- HuggingFace. Wordpiece Tokenization
- Sanh, Victor & Debut, Lysandre & Chaumond, Julien & Wolf, Thomas. (2019). DistilBERT, a distilled version of {BERT:} smaller, faster, cheaper and lighter. https://arxiv.org/abs/1910.01108.
Found this useful? Subscribe to our newsletter or share it.

Data Science & Search Intelligence Platform Team